Concepts
Automatiko is based on the concept of modeling business logic and decisions to capture and express business requirements. It is all about using this model to understand and explain what the service is about.
Workflow
Workflow (aka process) is the main entry point of the service. Depending on the language, a workflow can be expressed either as flow chart (in case of BPMN2), or a text-based format (JSON or YAML in case of Serverless Workflow).
A workflow consists of activities that are executed within the life time of each of its instances. These activities have different meaning depending of their type or place in the workflow model, such as:
-
Activities that invoke services ('service task' in BPMN or 'operation state' in Serverless Workflow)
-
Events that either capture events or produce events
-
Subworkflows that creates new workflow instance of another workflow to build hierarchy of workflow instances and take advantage of workflow composition pattern ('call activity or reusable subworkflow' in BPMN or 'subflow state' in Serverless Workflow)
Workflow as a Service (WaaS)
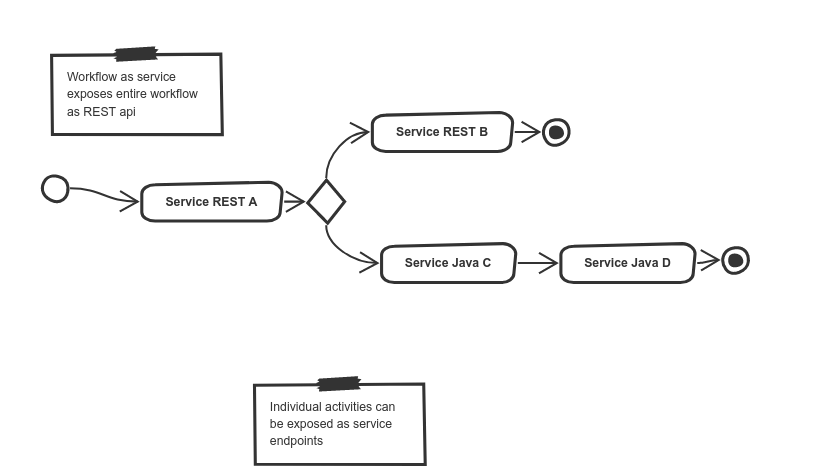
Workflow as a service brings an idea of modeling a service as a workflow. In this scenario a workflow is exposed as a fully featured service with a dedicated (domain specific) API. Workflow as a Service aims to cover more traditional service deployments that usually consists of:
-
a service API exposed over
http/rest -
an
OpenAPIdefinition for describing services to simplify their use -
taking advantage of various integration mechanism to be able to exchange data with different services/systems
-
ability to be either short lived or long running
Workflow as a Service does not really differ from any other developed service. The main advantage it provides is the ability to use the mentioned well established and known workflow languages such as BPMN and DMN as programing languages. Other features are for the most part very similar to those that could be coded by hand.
Workflow as a Function (WaaF)
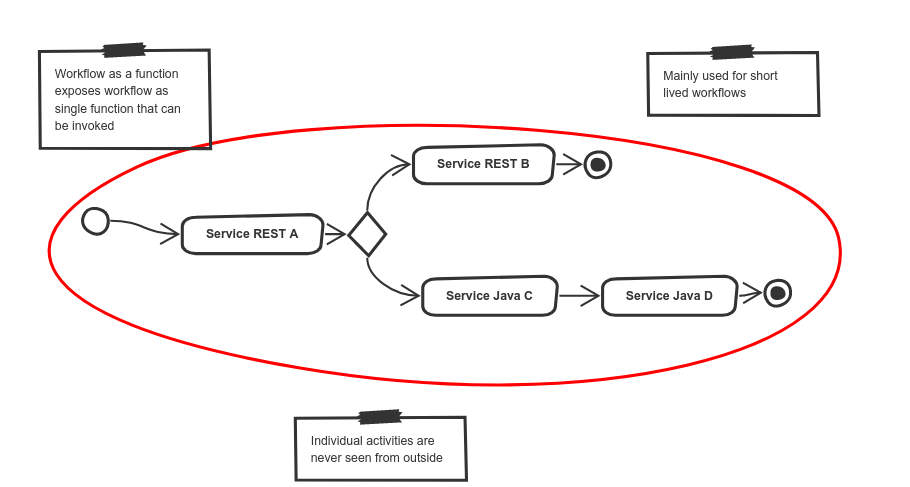
Workflow as a Function is dedicated for short lived operations that usually last no longer that a second. They are expected to be fast and small in size both at runtime and at boot time.
Workflow as a Function typically targets deployments in more constrained environments such as:
however are not strictly limited to them, as they can easily be invoked
over HTTP with both POST and GET endpoints, making them deployable virtually
anywhere.
Functions can map data from payloads (POST) as well as from query parameters
(GET).
|
Regardless of the number of activities it contains, the workflow is always
exposed as a single function with its id being its public identifier, namely the function name.
Workflow as a Function Flow (WaaFF)
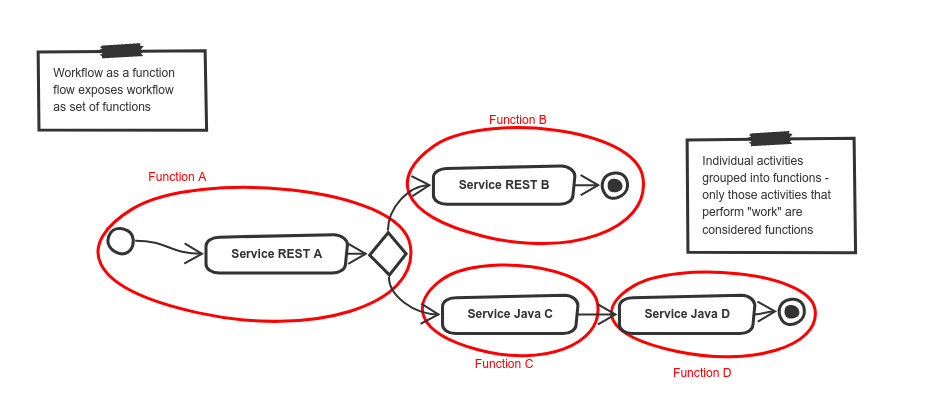
Workflow as Function Flow is a more advanced extension to Workflow as a Function which breaks the workflow into many different functions.
A function, in workflow terms, is a single executing activity. This single
activity can be grouped with other activities that do not actually perform work but
can be one of the following:
-
start or end of the workflow
-
control logic (gateways)
-
pass-through activities
In the diagram above again we see the same workflow example as used in the WaaS and WaaF scenarios. This time however we can break it up into multiple functions:
-
function
Adefines the start of the workflow instance function and it consists of three activities (start,service A, and the`gateway`) -
function
Bdefines the second function and it consists of two activities, namelyService REST Bandend. It is invoked when a decision was made to invoke "Service REST B". -
function
Cdefines the third function which is invoked when a decision is made to invokeService Java Cand. It consists only a single activity (Service Java C) -
function
Dis the last function that is invoked directly afterFunction Cand consists of two activities (Service Java Dandend)
All functions (except "Function A" which defines the workflow start) are invoked automatically based on the execution context. This means that a function, during its execution, can identify the next function to be invoked. This decision is influcenced by both the workflow definition as well as workflow data.
Workflow as a function flow always the exchanges of data as events in CloudEvent format.
It target deployment environment is Knative Eventing in order to take advantage of
its routing capabilities for events.
Identification and description
A workflow must include an assigned id. The id serves as an unique workflow identifier and as such should be:
-
short (typically a single word, or a compound word using the CamelCase naming convention)
-
descriptive (carry only the most important information)
The reason why these rules are describe is that the workflow id here is again used as your service identification parameter. With that said, it will be the top level resource of the workflow REST API.
| Best practice is to think about workflow id in context of its domain. For example the id of a workflow managing orders should be orders |
In addition to the id, a workflow also contains a name that should be provided and include a description of the logic encapsulated by the workflow definition. It should however not be too long as workflow allows you to define extra documentation on various other levels such as:
-
the workflow itself
-
every workflow activity
-
every data object (a.k.a. variable) in the workflow
-
every event defined in the workflow
Using documentation is recommended as it automatically enhances the service description. This allows service consumers to better understand the overall intention of the service which can aid with their integration efforts.
Versioning
Versioning of a workflow should be considered from the very beginning as it might have severe impacts on service consumers and its maintainability.
Following are the basic principles to how to handle versioning in Automatiko:
-
a version can be assigned to any workflow (public and private)
-
version will be part of the service contract - in REST api it will prefix the paths e.g.
/v1/ordersor/v1_2/ordersfor versions1and1.2respectively. -
multiple versions of the workflow should be kept in the same service, meaning a new version should be a copy of the previous one
| Change the version only when there is good reason for it. As a rule of thumb it is recommended to not change the workflow version if the change is backward compatible. In other words, change the version only when the modifications to the workflow make the existing instances impossible to continue. |
Types of workflows
| workflow types are currently only supported in BPMN language and not in Serverless Workflow. |
Workflow types defines the visibility of given workflow on the service API. There are two types of workflows:
-
Public - exposed as top level service endpoints
-
Private - hidden from the service API, meaning instances of such workflows cannot be started from outside.
| Private workflows provide a perfect fit for subworkflows. This allows you to limit the creation of new instances of subworkflows only to their, so called, owning workflow instance. |
Workflow data
Workflow data defines the actual domain of the service that is being modeled. In the end, all services are meant to deal with data and as such alter it.
Properly defining the workflow data model is extremely important to the service and the contract it will expose. To help with that, Automatiko promotes the use of so called tags to annotate and enhance data handling.
Data object tags
Workflow data, also known as data objects or variables, can be annotated with tags to enable additional features:
| Tag name | Description |
|---|---|
input |
Marks a given data object as input that should be available upon starting a new instance |
output |
Marks a given data object as output that will be always returned when an instance is altered or is completed |
internal |
Marks a given data object as internal, meaning it not be visible from the outside |
sensitive |
Marks a given data object as sensitive, meaning it not be visible from the outside and is not published via events |
notnull |
Marks a given data object as non-nullable, meaning once it was assigned a value it cannot be reset to null |
readonly |
Marks a given data object as read only, meaning that it cannot be changed after being set once |
required |
Marks a given data object as required to start new instance |
auto-initialized |
Marks a given data object to be auto initialized upon start, meaning it guarantees that the value will be set |
business-key |
Marks a given data object to be used as a business key of the instance. Applies only for the start of a new instance |
initiator |
Marks a given data object to be the source of initiator of the instance instead of relying on security context |
versioned |
Marks a given data object to be versioned. Each change to the variable records the previous one and makes it available
to be fetched with construct |
| Serverless Workflow does not define data objects explicitly and allows to have data pushed on demand and thus do not make use of tags. |
Workflow instance
Workflow instance is an individual instance of a given workflow. This is a runtime representation of a single execution according to given workflow definition.
Depending on the workflow definition (how it was modeled), a workflow instance can be short lived or it can span hours, days, months and more.
Each workflow instance is uniquely identified with generate id (of a form of UUID). This id remains unchanged during the entire life time of the instance.
Business key
Business key can provide an alternative to the workflow instance id. Similarly to the id, a business key, when assigned, remains unchaged during the entire live-time of the workflow instance. A business key can be used exactly as id and can be used to reference a given instance from the outside via service API.
| Even though business key is assigned the generated id can still be used to reference the instance. |
| Business key must be unique within the scope of a workflow (or version of the workflow). That means you can have only one active instance with a given business key. |
Execution timeout
Execution timeout of an instance can be defined within the workflow definition as part of custom attributes.
It allows to specify the maximum amount of time (since the start) that workflow instance is allowed to
remain active. It is given as a ISO formatted duration PT5H, P5D (5 hours and 5 days respectively).
To define it add timeout custom attribute on the workflow definition with desired duration
|
End of instance strategy
When workflow instance reaches its end (either by completing successfully or by being aborted) there might be situations that requires it be handled in one way or another. For this exact purpose, end of instance strategies are provided. These allow to have different behavior depending on your needs. For example due to legal requirements instances must be kept for given amount of time, or they should be archived to another location for reference.
Automatiko provides three out of the box strategies:
-
remove
-
keep
-
archive
Remove
Remove strategy is the default one that simply removes the workflow instance from the data store. That operation is permanent and by that means the information about the workflow instance (including its data) are gone.
This strategy helps at keeping the storage to minimum size by holding only instances that are not yet finished.
Configuration of this strategy
| Property name | Environment variable | Value |
|---|---|---|
quarkus.automatiko.on-instance-end |
QUARKUS_AUTOMATIKO_ON_INSTANCE_END |
remove |
Keep
Keep strategy is the opposite of remove, it will update the status and its content and keep the workflow instance in the data store. That will allow to access completed and aborted instances at any time, including their data and complete execution path that can also be visualized on the workflow definition image.
| Keep strategy comes with limitation that does not allow to reuse the same identifiers of workflow instances. In most of the cases this is not an issue as identifiers are generated. The situation when this can manifest itself is when workflow instances uses business keys. These are considered alternative identifiers and by that cannot be reused. |
Configuration of this strategy
| Property name | Environment variable | Value |
|---|---|---|
quarkus.automatiko.on-instance-end |
QUARKUS_AUTOMATIKO_ON_INSTANCE_END |
keep |
Archive
Archive strategy allows to automatically extract complete set of information about workflow instance at its completion. That data are then exported into an archive (zip file) that consists of
-
process instance export format
-
each variable as separate file (regular variables as json documents, files as dedicated files with proper extensions)
Archives are by default stored on file system so extra configuration property is required. Although this
is also extensible and custom implementations of io.automatiko.engine.api.workflow.ArchiveStore
can be provided that will be used to store the produced archive.
Archives will be stored in the given directory grouped in folders named based on workflow definition
id and version. Each archive will be named like {workflow-instance-id}.zip where {workflow-instance-id}
is going to be replaced with actual id of the workflow instance.
Configuration of this strategy
| Property name | Environment variable | Value |
|---|---|---|
quarkus.automatiko.on-instance-end |
QUARKUS_AUTOMATIKO_ON_INSTANCE_END |
archive |
quarkus.automatiko.archive-path |
QUARKUS_AUTOMATIKO_ARCHIVE_PATH |
/my/custom/archive/folder |
Tags
Similar to workflow data tags, a workflow itself can define tags. Tags allow you to put extra information (in addition to a business key) used for correlation purpose.
Tags can be both simple (constant) values that won’t change over time or expressions that are evaluated every time a workflow instance changes.
Additional feature of workflow tags (compared to workflow data tags) is that tags can be added and removed during the entire life time of a workflow instance.
| Tags defined in a workflow (definition) cannot be removed. Only tags added on top of active workflow instance can. |
Decisions
Decisions are used to capture the workflow decision logic. They are not exposed as a separate services but instead are invoked from within a workflow. Decisions in Automatiko are defined as DMN diagrams which goes hand in hand with BPMN to have both defined in a graphical way.
Best practices to properly integrate decisions include:
-
decisions should be identified by
modelandnamespaceand optionallydecisionordecision service -
decisions must define inputs which will then be mapped from the workflow data
-
decisions define various decision logic constructs such as
-
literal expression to encapsulate expression like decisions
-
decision tables
-
Decision results are then mapped (by name) to workflow data.