Error handling and retries
Regardless of what use case given service implements (be it event streams, IoT, etc) there is always a need to handle unexpected situations.
Automatiko comes with built in error handling for operations that are being executed as part of the workflow instance. Error handling can be applied to
-
individual activities
-
subworkflows
-
entire workflow instance
Errors are usually identified via error code that is used to find correct
error handler (error event node) inside the workflow definition.
Defining errors
Whenever there is a potential that given activity can result in an error then error handling should be defined for it.
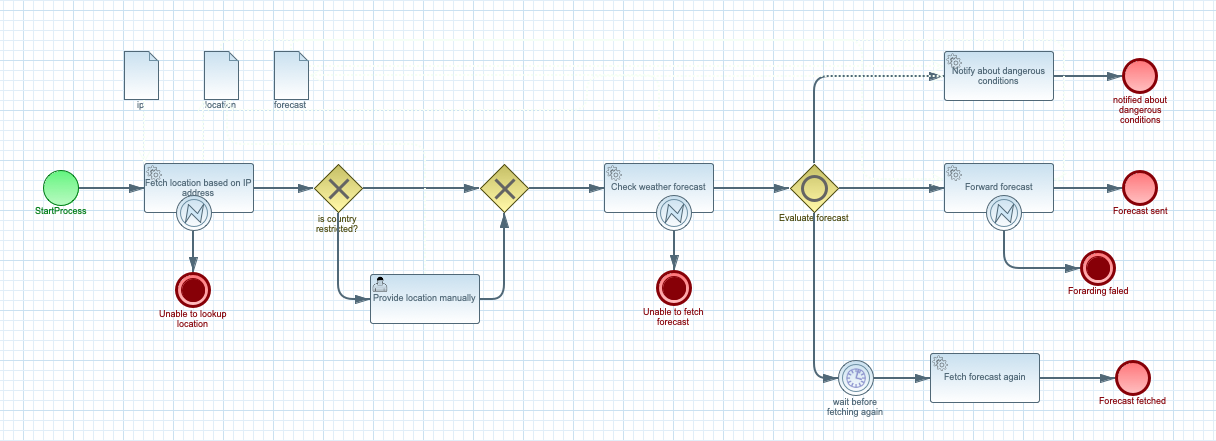
In the above example there are three activities that can result in an error
-
Fetch location based on IP address
-
Check weather forecast
-
Forward forecast
Two first activities are REST calls, while the third one is simple Java service (method invocation) that every third call with throw an error.
In this scenario error handlers (error event node) is attached to given
activity that means it is only active when the node it is attached to is active.
| Error handlers always cancels the activity they are attached to and take the alternative path |
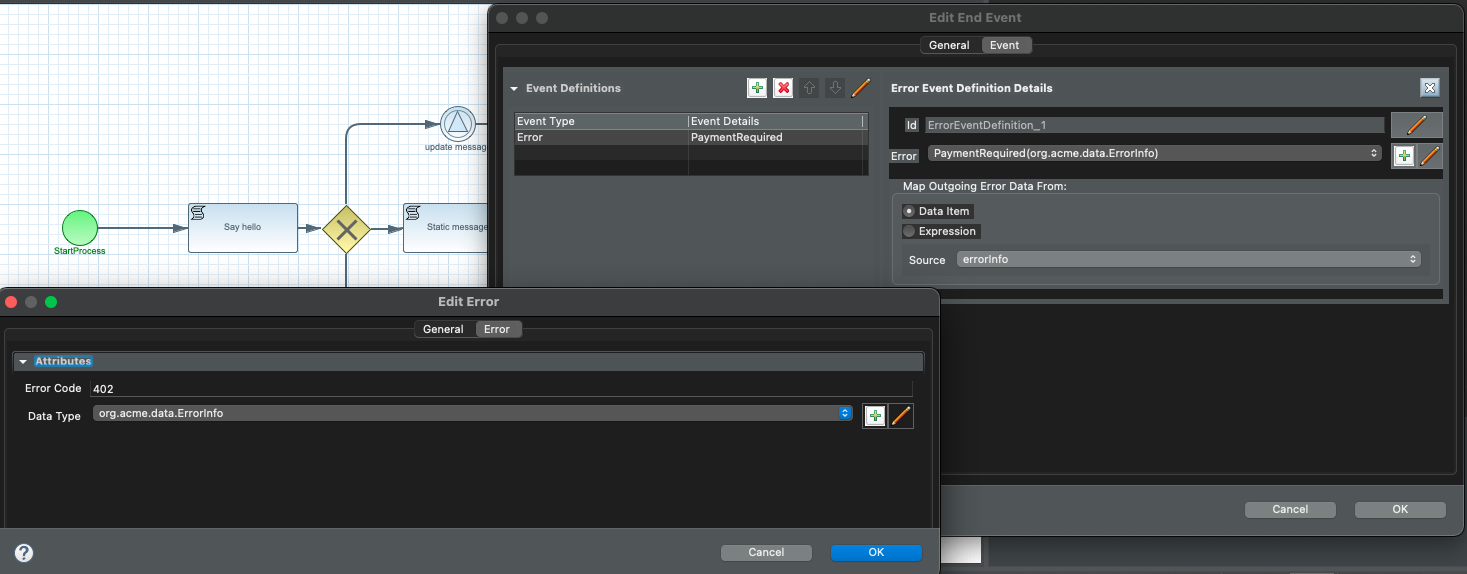
To be able to handle errors, error itself must be defined. It can be done directly
on the event handler (error event noode) by editing error definition
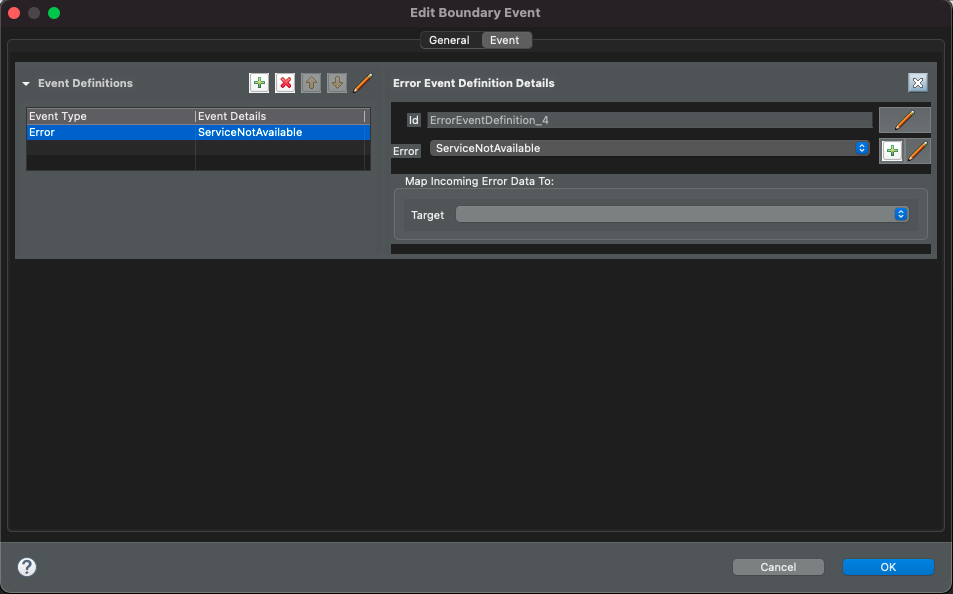
Clicking on the plus icon button allows to create new error, clicking on the
pencil icon button allows to edit existing error.
|
Error handlers can map the error details to a workflow data object so it might be used to troubleshoot given error.
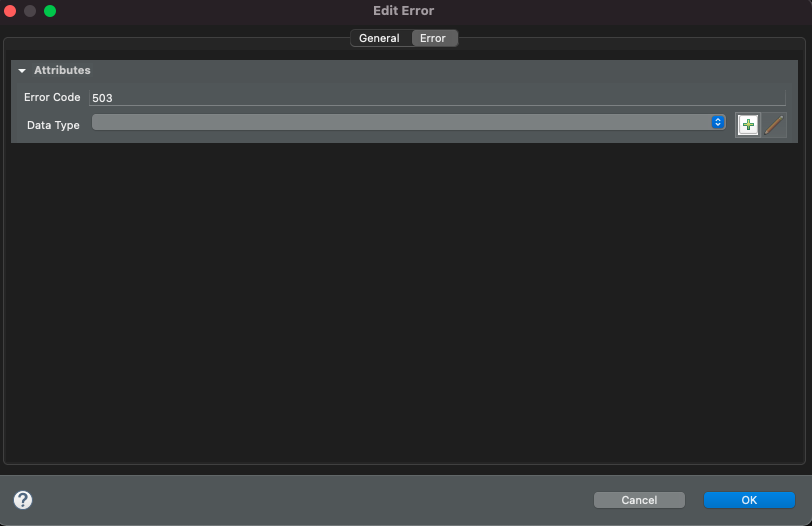
Most important parts of error definition is
-
name - name of the error so it can be easily understood
-
error code - the text value that uniquely identifies type of error
-
data type - optional data type of the error being produced which can be mapped to data object of the workflow instance
Services that are custom can make use o this error handling by throwing
exceptions of io.automatiko.engine.api.workflow.ServiceExecutionError type.
It allows to set the error code that will be used by the workflow instance
to locate the error handler and the root cause of the error.
Aborting workflow instance with an error
Sometimes the business logic can lead to an error state that should abort process instance. An example of that is when provided information is not valid and thus should not be used to continue with execution. In such a case an error should be returned to the client to indicate this condition.
To be able to define this use case as part of the workflow, a workflow definition can take advantage
of error end events as illustrated below.
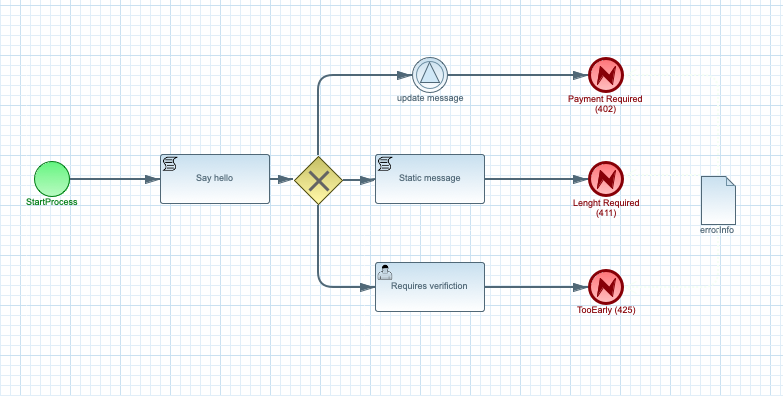
Such error end events use the same error definition as described above.
Errors based on error end events are part of service interface (REST and GraphQL)
and will then use error code as response code or message to provide valuable information to the
consumers of the service.
|
Error end events cause workflow instance to complete with an error and return to the consumer.
It’s important to note that upon such an error the workflow instance data are not sent but instead
the error data. With that in mind, setting error data (that is usually a subset of workflow instance data)
is important.
| This logic also applies to event based subprocesses with error start event. The reason for this is that error start event always cause workflow instance to abort. |
Retries
One of the most common requirements around error handling is retries. Sometimes errors are temporary like network glitch, short outage of a service etc. In such scenarios there should be an easy way to let the operation to retry instead of directly taking the error path defined in the workflow.
Automatiko comes with built in retry mechanism that allows you to define two attributes to control retries
| Attribute name | Description | Default value |
|---|---|---|
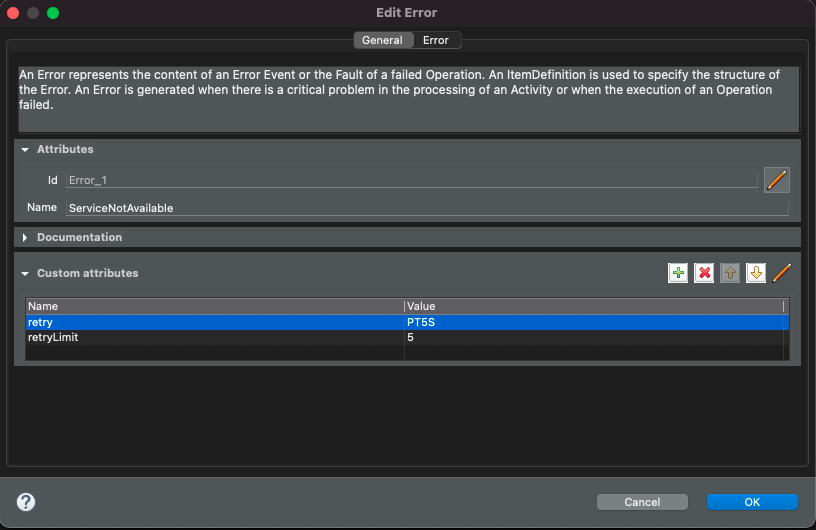
retry |
Defines time interval that triggers retry, it is an ISO format duration e.g. PT5S to retry every 5 seconds |
No default value |
retryLimit |
Defines how many retries there should be before triggering error handler and take the error path |
3 |
retryIncrement |
Duration which will be added to the delay between successive retries (ISO 8601 duration format) |
PT5M |
retryMultiplier |
Value by which the delay is multiplied before each attempt |
1.5 |
Retry attributes are defined on the error itself via custom attributes
There is no need to make anything more to automatically benefit from built in error handling and retries.
| When using process management addon there is an instance visualization that will mark activities that are in retry with a warning icon. |
Automatic error recovery
During execution, unhandled errors will put workflow instance into an error state. This means that it requires additional action to resolve the error and resume execution. There are two possible ways of recovering from error state:
-
retry the failed node
-
skip the failed node
Retry means that the same node will be executed once again. Depending on the error, retry might already resolve the problem (in case it was an temporary problem like lost network connection or similar). But in other situations it might require additional action to be performed - like updating data objects of the workflow instance.
On the other hand, skipping means that the failed node won’t be executed at all and execution will be resumed from the next node in the workflow definition.
Automatiko comes with an addon that aims at automating error recovery based on time scoped retry mechanism. Each failed instance will be scheduled for automatic retry which by default will
-
run every 30 seconds
-
attempt to retry it at most 10 times
| It’s important to note that automatic error recovery does not perform any other action that retry of the failed node. |
Use it
First of all, a dependency to automatiko-error-management-addon needs to be added to the project.
<dependency>
<groupId>io.automatiko.addons</groupId>
<artifactId>automatiko-error-management-addon</artifactId>
</dependency>Following are parameters that can configure this addon to have more control on how it behaves
| Property name | Environment variable | Description | Required | Default value | BuildTime only |
|---|---|---|---|---|---|
quarkus.automatiko.error-recovery.delay |
QUARKUS_AUTOMATIKO_ERROR_RECOVERY_DELAY |
Specifies delays for error recovery attempts as ISO 8601 period format |
Yes |
PT30S |
No |
quarkus.automatiko.error-recovery.excluded |
QUARKUS_AUTOMATIKO_ERROR_RECOVERY_EXCLUDED |
Specifies comma separated package names (of workflows) to be excluded from error recovery |
Yes |
No |
|
quarkus.automatiko.error-recovery.max-increment-attempts |
QUARKUS_AUTOMATIKO_ERROR_RECOVERY_MAX_INCREMENT_ATTEMPTS |
Specifies maximum number of recovery attempts |
Yes |
10 |
No |
quarkus.automatiko.error-recovery.ignored-error-codes |
QUARKUS_AUTOMATIKO_ERROR_RECOVERY_IGNORED_ERROR_CODES |
Specifies comma separated error codes that should be ignored from error recovery |
Yes |
No |
|
quarkus.automatiko.error-recovery.increment-factor |
QUARKUS_AUTOMATIKO_ERROR_RECOVERY_INCREMENT_FACTOR |
Specifies increment factor in gradually increase the delay between attempts. Expected values are from 0.1 to 1.0 |
Yes |
1.0 |
No |